I ran into this strange issue the other day in my homelab, and it is worth sharing it: I was trying to setup a highly available Team Foundation Server data tier with AlwaysOn Automatic Seeding instead of the usual backup and restore process, but the TFS_Configuration database (for some reason) was not collaborating.
Automatic seeding of availability database 'Tfs_Configuration' in availability group 'TFSAG' failed with an unrecoverable error. Correct the problem, then issue an ALTER AVAILABILITY GROUP command to set SEEDING_MODE = AUTOMATIC on the replica to restart seeding.
We are talking about a plain, empty instance, so... it was a bit of a needle in a haystack!
Let's take a step back: SQL Server AlwaysOn Automatic Seeding is a new feature of SQL Server 2016 and above that manages to sync up a database in an Availability Group without leveraging backup and restore. This is a life saver in certain situations, so that you can avoid the computational load of a backup and of a restore that might take a long time.
There are some constraints - above all, the instances making up the Availability Group must be *identical*. Yes, identical in everything, including paths used by SQL Server. It is a very cloud-first approach at the end of the day, where you have identical, commodity resources at your disposal and your actual target is to provide a friction-less experience to whom is going to consume the service you'll offer.
So cool, right? Still, for some reason, my Configuration database didn't stream from Primary to Secondary replica. I checked the DMV, and I got an obscure 1200 failed_state error - Internal Error.
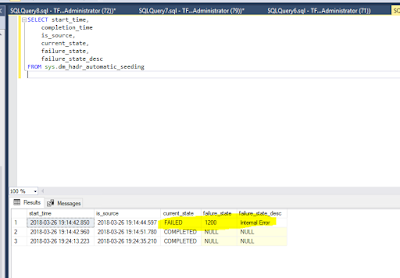
The first thing I did (as the instances are really identical, they were provisioned the day before) was to check that I was on the latest CU, as there are fixes available for Automatic Seeding. Check.
I had a look at the script used by the wizard to add the databases to the Availability Group, nothing too fancy to be fair. Reading around seems that there is still a chance that things might suddenly break, so I took another path.
Yes, a Full Backup (taken with the TFS Administration Console nonetheless) was supposed to be enough to enable Automatic Seeding as the recovery chain is started. Would another Transaction Log backup hurt? I don't think so.
After taking the faulty database off the Availability Group, I ran the speedy Transaction Log backup and added the database back in the Availability Group with the script. Guess what, it worked! And my new TFS instance is up-and-running.
Of course this is totally transparent as usual for TFS, as the configuration wizard is smart enough to set the right connection string from the beginning. But you still need to make sure the Availability Group is correctly set, otherwise at the first failover you will be left with nothing.
Automatic seeding of availability database 'Tfs_Configuration' in availability group 'TFSAG' failed with an unrecoverable error. Correct the problem, then issue an ALTER AVAILABILITY GROUP command to set SEEDING_MODE = AUTOMATIC on the replica to restart seeding.
We are talking about a plain, empty instance, so... it was a bit of a needle in a haystack!
Let's take a step back: SQL Server AlwaysOn Automatic Seeding is a new feature of SQL Server 2016 and above that manages to sync up a database in an Availability Group without leveraging backup and restore. This is a life saver in certain situations, so that you can avoid the computational load of a backup and of a restore that might take a long time.
There are some constraints - above all, the instances making up the Availability Group must be *identical*. Yes, identical in everything, including paths used by SQL Server. It is a very cloud-first approach at the end of the day, where you have identical, commodity resources at your disposal and your actual target is to provide a friction-less experience to whom is going to consume the service you'll offer.
So cool, right? Still, for some reason, my Configuration database didn't stream from Primary to Secondary replica. I checked the DMV, and I got an obscure 1200 failed_state error - Internal Error.
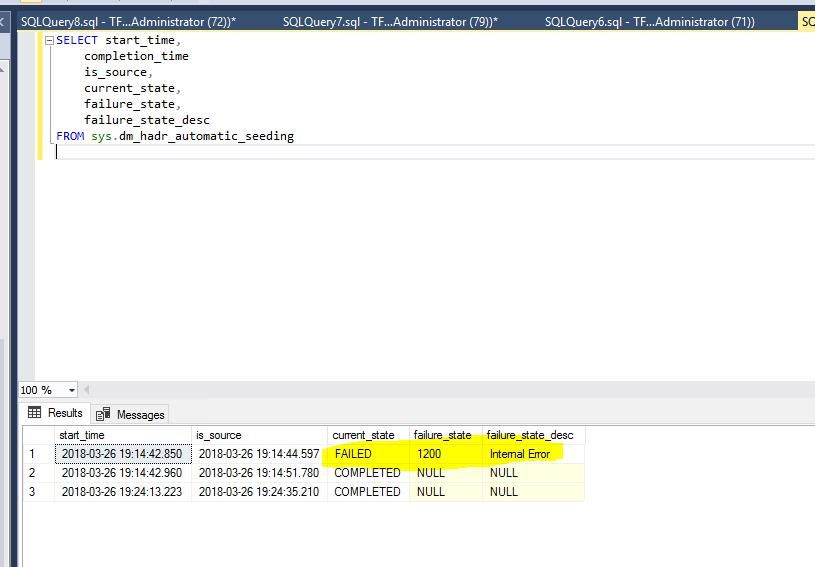
The first thing I did (as the instances are really identical, they were provisioned the day before) was to check that I was on the latest CU, as there are fixes available for Automatic Seeding. Check.
I had a look at the script used by the wizard to add the databases to the Availability Group, nothing too fancy to be fair. Reading around seems that there is still a chance that things might suddenly break, so I took another path.
Yes, a Full Backup (taken with the TFS Administration Console nonetheless) was supposed to be enough to enable Automatic Seeding as the recovery chain is started. Would another Transaction Log backup hurt? I don't think so.
After taking the faulty database off the Availability Group, I ran the speedy Transaction Log backup and added the database back in the Availability Group with the script. Guess what, it worked! And my new TFS instance is up-and-running.
Of course this is totally transparent as usual for TFS, as the configuration wizard is smart enough to set the right connection string from the beginning. But you still need to make sure the Availability Group is correctly set, otherwise at the first failover you will be left with nothing.