Like I said in the previous post, modern deployment patterns are not an exclusive of the OTT providers and they are not something that requires using cloud technologies.
After Rolling Deployments, another very common pattern you might want to tackle is Blue-Green deployments. In a nutshell, it means having two identical environments to use in order to deploy new versions of your application with minimal downtime.
It is a bit harder compared to a Rolling Deployment – mainly because there could be countless variations on the technical details, depending on how your environment is composed, but let’s try to jot down a skeleton version of a Blue-Green pipeline you can use.
So in my case, I am using the same application I used in the previous post, with an additional environment (which happen to be a cluster, just to keep things a little more realistic). This is what my pipeline looks like:
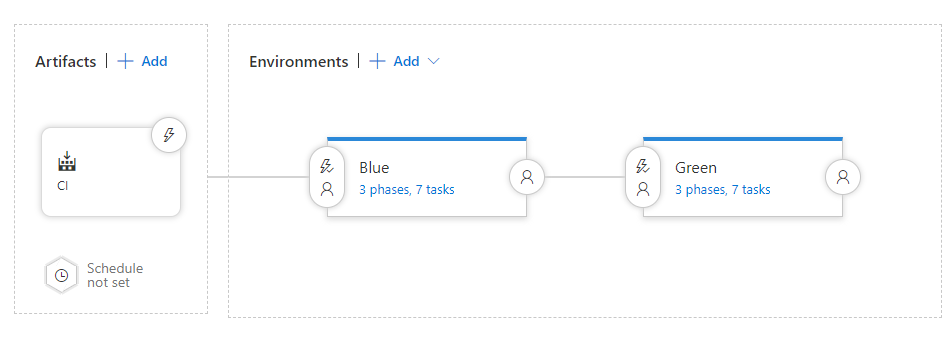
Each environments follows the following process:
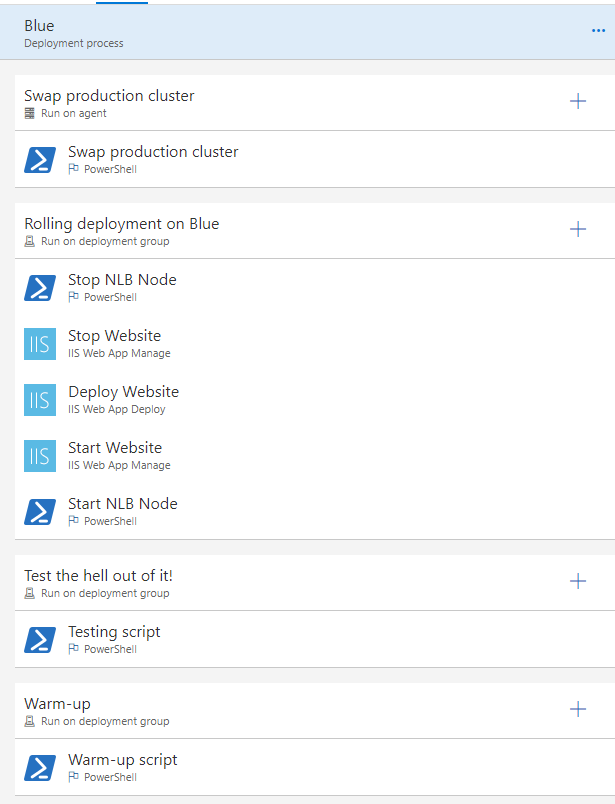
Let’s say we are running all of this against the blue cluster, which is currently production.
The first phase is an Agent Phase – it swaps production traffic from the blue cluster to the green one.
I want it to be independent from the environments so that it can deal with the router that manages traffic between the two clusters. As I do not have an appliance or anything special in front of them (I am just playing with CNAME records in my lab domain) this ensures the process is not tied to any machine.
Moreover, this pipeline is designed to be used just after everything is deemed production-ready, so if it fails it is not meant to be ran again without a hitch.
The reason behind this choice is that I wanted to share a general idea of how to do this on-premise, and there might be so many permutations of what you might need to do or what could go wrong that my example with all the possible fail safes in place would have been way too complex.
Up next, the Rolling Deployment we saw in the last post for both nodes of the blue cluster, one at a time.
Then, even if you are running this for a production application you still need to make sure your smoke tests are passing. This is literally the last line of defense before the switch.
Eventually, a warm-up script to ensure that my application is responding correctly when it is going to be used from my users.
Now the magic happens: as soon as you move to the second Environment, traffic is switched to the blue cluster again (which is done with the v2, and warm enough for production traffic) in a seamless way while the whole process goes on against the green cluster.
Of course, there are some things to consider. The first one, is that this pipeline is not designed to be a commit-to-production pipeline: there is no backup mechanism in it and no revert process if one environment fails (this lives with the fact that you should already have the pipelines defined in the previous post though 😊).
You want to use approvals to manage the switch from green to blue, so that only when it is checked then you can go ahead.
Eventually (this is quite important though), your application must be able to cope with environment change – it should be message-based, or stateless. Traditional stateful applications can have problems with it, which can be mitigated with message queues for example, so we are back to square one 😊