This is the first of a (hopefully!) series of posts looking at the substantial new features of Azure DevOps Server, which was released yesterday in RC1.
Why? Well, since it is a quarterly snapshot of the code from the service it seems excellent value in terms of what it offers once brought on-premise!
This is quite an important feature I reckon: Azure DevOps Server now supports Azure SQL Database as the Data Tier.

I can already see you are scratching your head, a little puzzled. Let's put some red lines here, shall we? This configuration works (not "is supported" - works!) only when you are running an Azure DevOps Server instance in an Azure VM. So this is already a huge restriction, but it makes sense - you cannot have better connectivity than something already within the Azure datacentre. After all, on-premise does not necessarily need to be inside a wholly-owned datacentre.
Also, when you create the Application Tier VM(s) you need to assign a System assigned Managed Identity to it - this is how the VM will authenticate with your database, and this is what will enable the Azure option in the deployment screen you saw before.
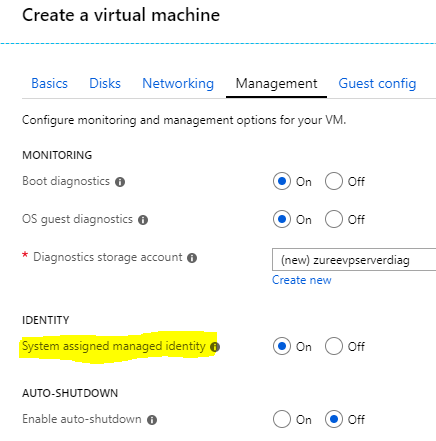
Also, you need to provision at least two empty databases in advance: the Configuration database (name it Tfs_Configuration, for now) and the main Collection database (again, Tfs_DefaultCollection?). Once you have these two up and running, you need to set an AAD administrator user and assign these roles to your databases:



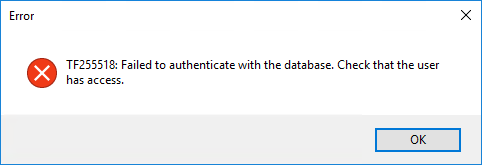
What if you don't run these? The wizard put a series of checks in place to prevent a botched configuration. Hence, if you don't run the first script you are not allowing the VM to authenticate against the Azure SQL Database Server, causing this error:
Without the second script you will get an explicit error during the Readiness Checks. Eventually, all databases should run an S3 tier or above, otherwise you will be prevented to configure the instance (for the Configuration database) or you will get various errors and your collection will not be provisioned.

Why all of this? Put yourself in the shoes of someone who deals with a 3TB Collection on a daily basis. Backups, storage, DBCC, hardware performance and high availability. Can you see the reasons why? 😀