Sometimes simple things seem really hard - rollback strategies seem to end up in this category!
Let’s make things simple: each and every release pipeline you create can have multiple jobs, and each job can have its own execution condition.
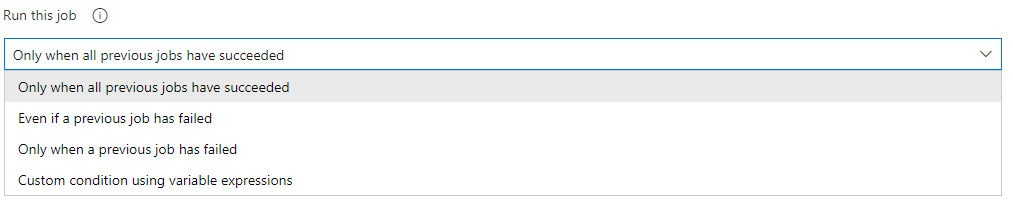
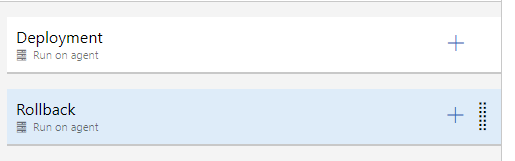
This means you should have, at a minimum, one job for your deployment and one for your rollback if something goes wrong:
The Rollback job will have this execution condition:
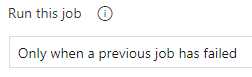
There you can run everything you need to restore your target stage - drop a database and restore it from a backup for example, together with an artifact rollback. Do not use a separate stage for this, as it creates confusion and potentially problems. Always add a rollback job at the end for this purpose.
And eventually, this is clearly true for both cloud and on-premise scenarios - there is nothing stopping you from doing this regardless of the target location. In case of an on-premise deployment you would use a Deployment Group job rather than an Agent job, that is the only difference.