All technology tools and platforms have some feature which, for one reason or another, are less known and used compared to others. More often than not, Conditions in Azure Pipelines fall within this category.
Out of ten Pipelines I see on any given day, at least eight will have everything chucked in a single Job. It is definitely not an optimal way of doing things.
Aside from the fact that Jobs are there for a reason (I might talk about this next time around) what shocks me the most is that people will come with the most convoluted ways to achieve what is effectively a trival goal given the right tools.
For example, let’s pick up an extremely common, simple yet very hard example: a database backup to run before running the pipeline.
Yes, if the database is a reasonable size it can be embedded somewhere. But what if it isn’t? In that case, you should think long and hard about it. How long will it take? Are you going to slow down your releases? Shall we start adding an extra stage before just for that?
Stop you there for a second. Do you need to run a backup every time? That alone is an answer that shapes the pipeline design. If not, then you need a Job that runs the backup only under certain conditions. Conditions you control.
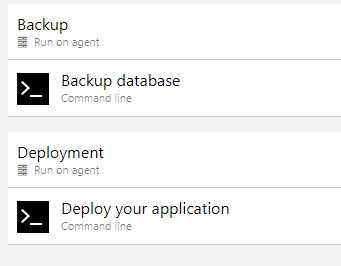
So, the database backup should not run by default, but it needs to be controlled when releasing. Easy peasy - first of all, create a scoped variable for each stage where this applies:

This variable controls our Job. Then the job needs to be configured to look for the value and act accordingly.
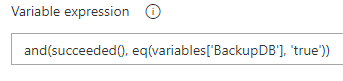
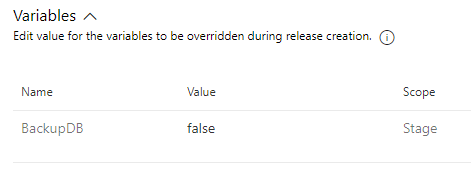
That’s literally it. Set the variable when triggering the release, and you are set:
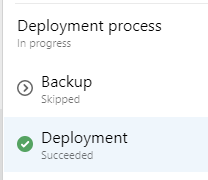
Features are there, documentation is plentiful, use them! :-)