Vibe coding. Many people are talking about it, some are practicing it avidly, some are wondering how to actually do it. This post is for you if you are in the latter camp, or if you want to find out more about GitHub Spark.
GitHub Spark is an experiment from GitHub Next, and I am particularly fond of it. It gives you a development enviroment, an execution environment, a data storage facility powered by a key-value database and access to LLMs all via…prompts. Yes, prompts. All the applications are built upon React, and despite Spark being designed around natural language and prompt engineering, it still gives you access to the code so you can tinker with it as needed.
I had ten minutes between meetings, so I wanted to try something more than a Hello World or a sample to do list 😀 I tried to replicate my notetaking framework. It’s something I have been using for over 20 years: a notebook I carry with me for day-to-day notes, relatively unstructured besides a topic header and a date, coupled with a second notebook stored in my office where I summarise notes by topic in a much more condensed and analytical way. The latter one has an index, which helps me find topics at a glance.
With this in mind, I told Spark what I wanted to do:

And I got my skeleton up and running:
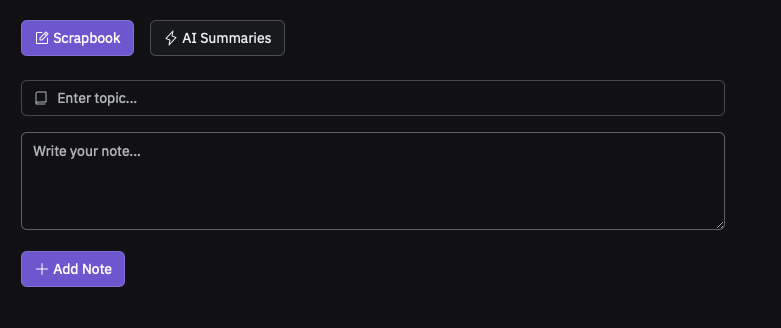
A couple more things…

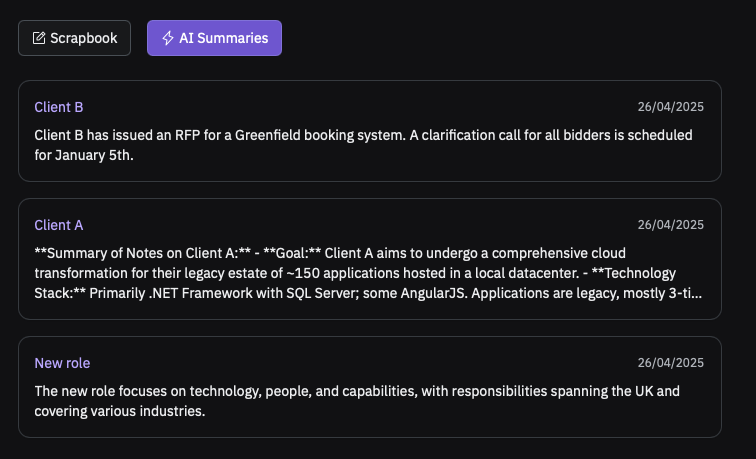
Now, with a few more prompts I added extra features such as favourites and notes export, but this is not really the point. GitHub Spark gives you a way of editing your application in a very simple way, either via manual edits or directly within the code:
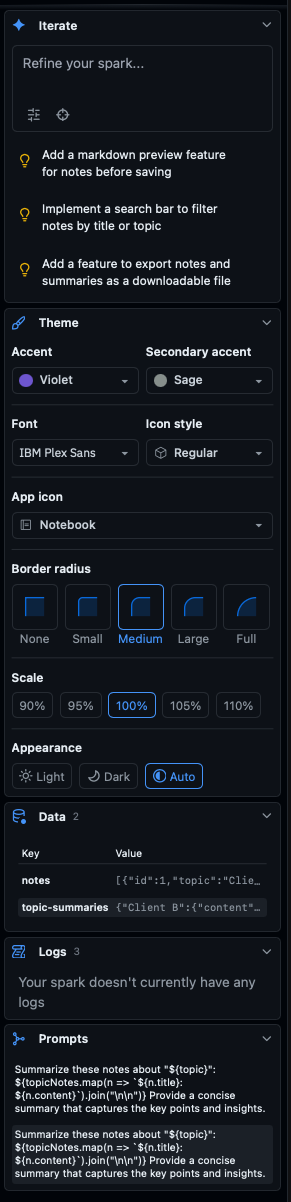
It gives you hints on what else you could add, a theme editor, a data explorer, logs and a way of adding prompts for LLB-backed features. It’s all there! And if you want to look at the code, you can:
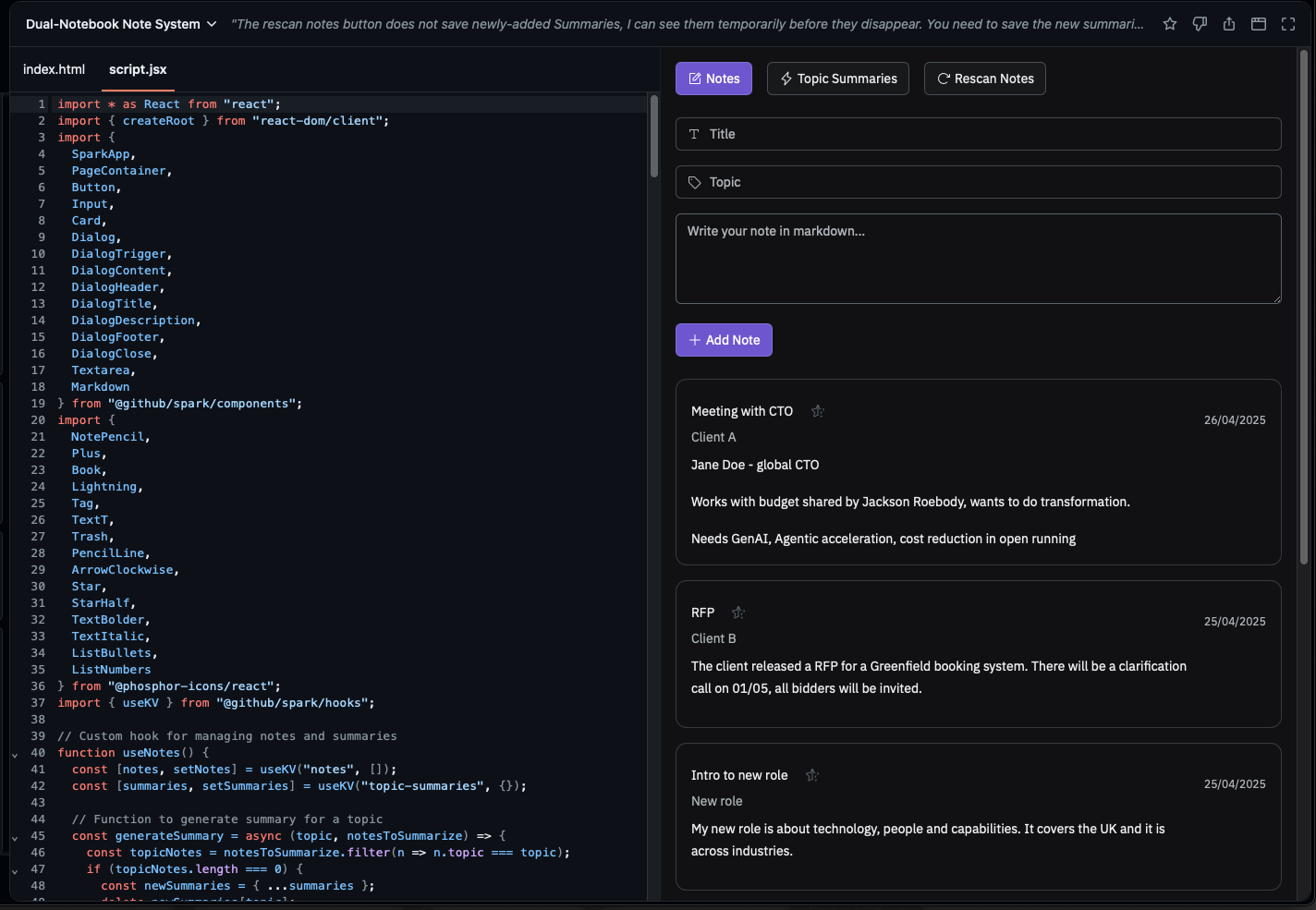
You can also choose different LLMs. I used Claude Sonnet 3.5 for most of this application, however it struggled with the data export feature so I switched to GPT-4o and I managed to get what I needed that way.
The data storage layer is also pretty interesting: it is key-value, but it’s also JSON-based so you can nest things as needed. This is an example from my Formula 1 result tracker:
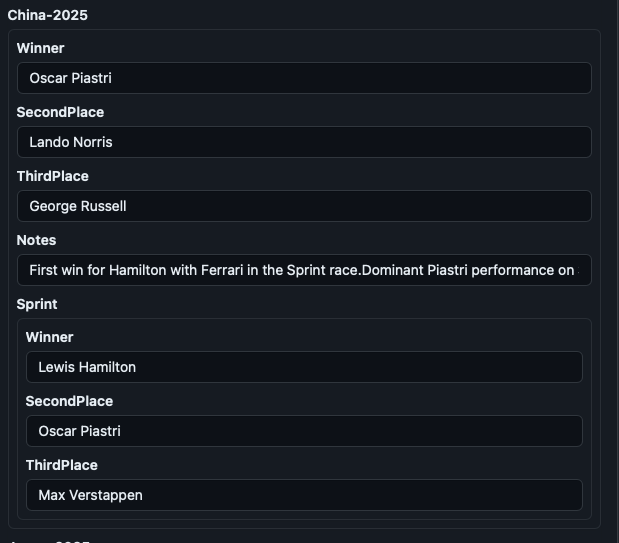
You are not limited to a single level of hierarchy, and it is quite flexible. This is how it would look once in the application itself:
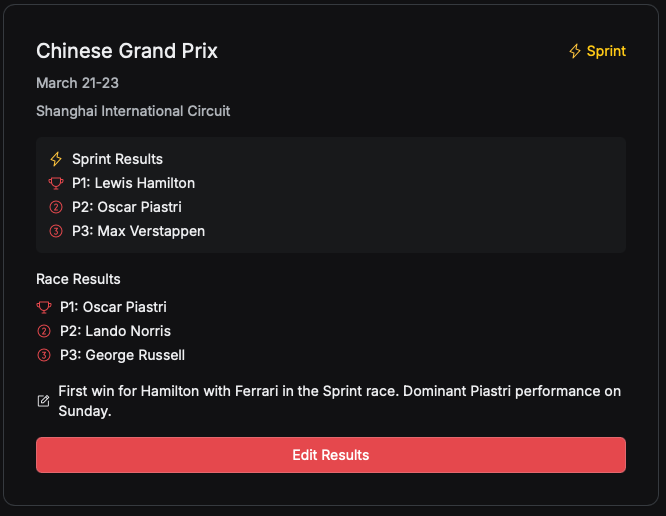
I am using it more and more to create simple things that accelerate my day to day, what I like the most is the fact that it does not require any more effort than this, and it is super-personalised. I hope GitHub will make Spark as accessible as possible as I truly believe it changes the way we think of custom applications.