How do you really harness GenAI in an engineering organisation?
I answer to this question at least once a day. And my (long) answer is hard to digest. It involves bottom-up empowerment and, most importantly, disruption. And with disruption, the reaction is always the same:
But we already have a critical programme of work we cannot slow down! Our engineers can’t get distracted with this.
Well let me tell you… you are on the road to irrelevance. Do you want an example? Let’s do this.
My persona
I haven’t worn a developer hat (professionally of course) in ages.
I can write code, I can help and troubleshoot, but ultimately I haven’t been a full-time engineer in over a decade, I would be doing a disservice to developers if I were to call myself one.
Yet I still dabble with code because I believe it’s critical to be able to remain at the forefront, and every good leader should put their money where their mouth is.
If I do something more than twice I script the hell out of it. Infrastructure as Code, automation and pipelines are second nature. Backend development is still fun. However I never liked any form of JavaScript, and I tended to avoid it. Until now.
My use case
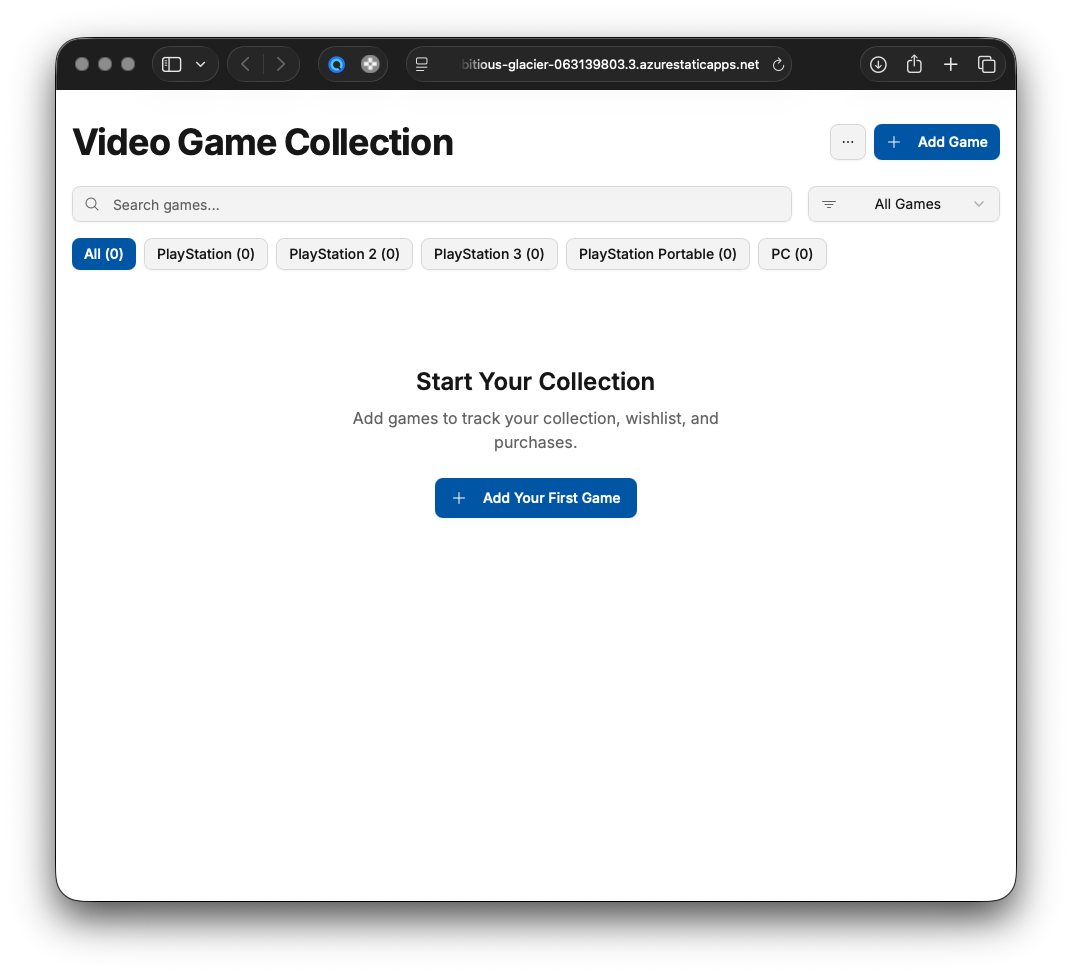
I am an avid retrogamer, to the point I have a CRT TV in my office as well as a number of consoles and a gaming PC. And to go with all of that, obviously, there is a spreadsheet keeping order in my game collection.
I decided to replace it with a simple web application, and rather than going the usual stack of .NET and my comfort zone, I decided to do things in an entirely different way: GenAI-first.
The initial prototype
As I said multiple times, I love GitHub Spark. It gives developers a way of seeing ideas turn to reality quickly and without the burden of scaffolding. So that was my initial choice:
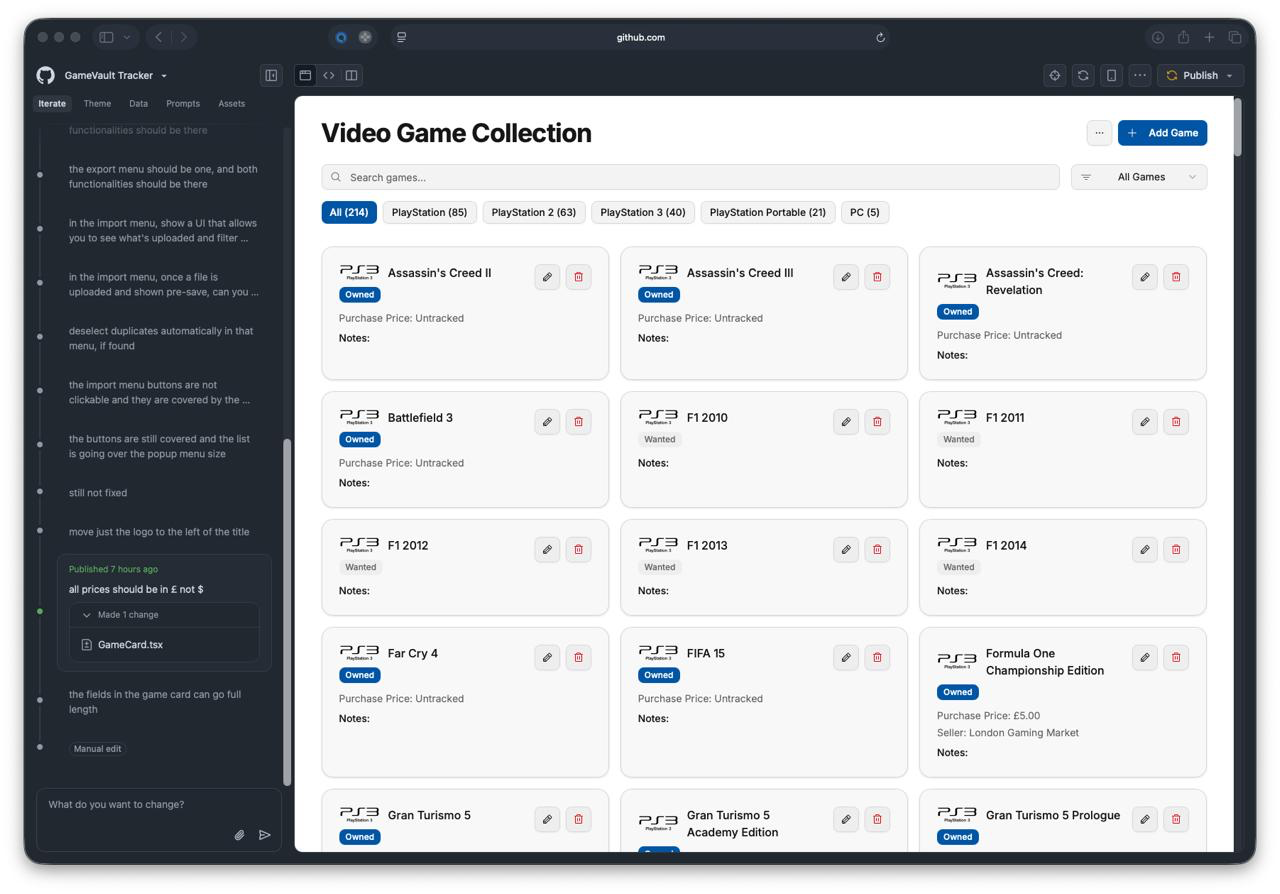
This took less than 30 minutes. It was mostly about explicitly calling out what I wanted, in detail, and iterating on small requests. My initial prompt was very big though, as I had listed out the features I needed.
This prototype is no small feat: it has CSV-based import and export logic with delta manipulation, category management, search and filtering, proper UI. It’s a real application, not a Hello World of sorts.
Leave the prototype alone!
Once you are happy with the result, Spark lets you publish a repository with the content of your Spark:
Now, this repo is a fork of the template GitHub uses for a Spark, but most importantly it is directly linked to your Spark that is running.
For this reason, you should not work on this repository unless you want to tinker with the frontend. Given we want to get to a real environment, you will need to tear the key-value store apart and replace it with another solution, breaking the Spark.
You should be doing what any developer in working in a real Agentic Engineering organisation would do: fork it from your local repo to another, organisational one. I happen to have this setup as well (account v organisation) so I forked it as-is into my organisation:

Now we are talking! A quick npm run build confirms it works on my machine. Or it loads, rather.
Getting on Azure
Infrastructure-wise, we will go for the bare minimum: an Azure Storage Account with Table Storage for my key-value storage, and an Azure Static Web App for the frontend. Simple enough.
The first thing to do once you go down this route is to modify the default GitHub Actions workflow that Azure creates when you link the repo to the Web App:
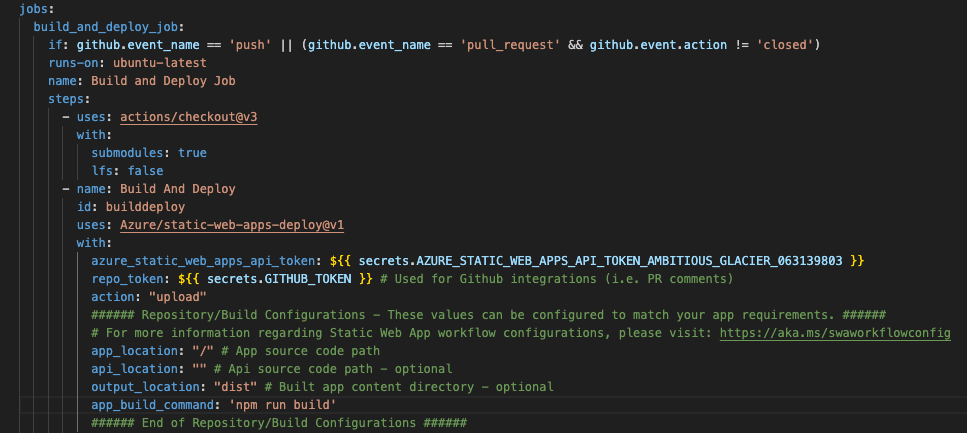
The app_build_command is needed because Spark uses Vite for building the app, and it’s not the default stack used in Azure. Don’t try any other way, it won’t work (changing the directory, etc.), easy enough though with a reasonable understanding of what you are doing.
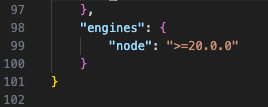
Also remember to change the Node version in the package.json file as the packages in use target Node 20+:
This will allow you to get a green pipeline and have an empty Azure application which cannot save data anywhere. Still, it’s outside of Spark now!
Agents for the heavy lifting
I definitely don’t want to start fiddling with code I haven’t written, especially in an unfamiliar environment: enter my GitHub Copilot Agent Mode, which will replace the key-value storage with the appropriate Table Storage calls:
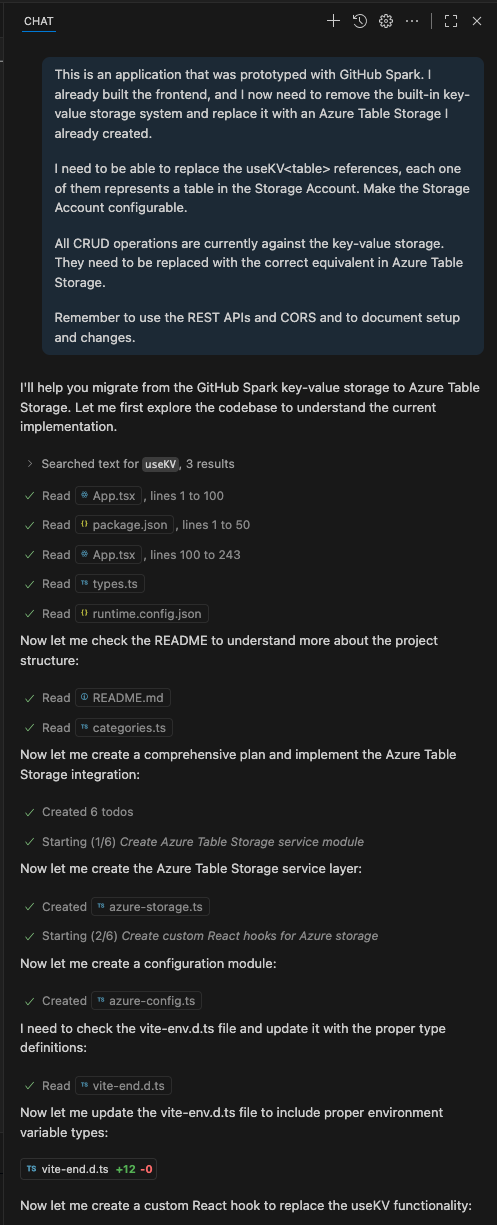
It worked for a while, and it not only implemented the logic but also generated plenty of documentation supporting everything. Except it did not work at all.
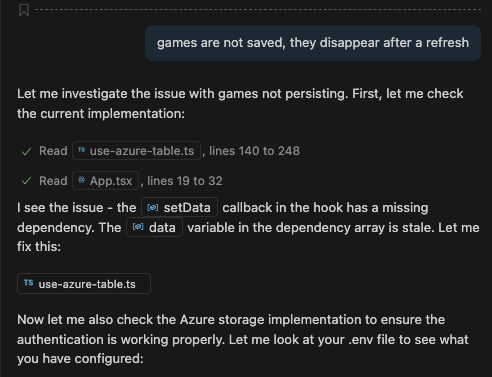
Interestingly enough, the final output was a list of potential troubleshooting steps to take:
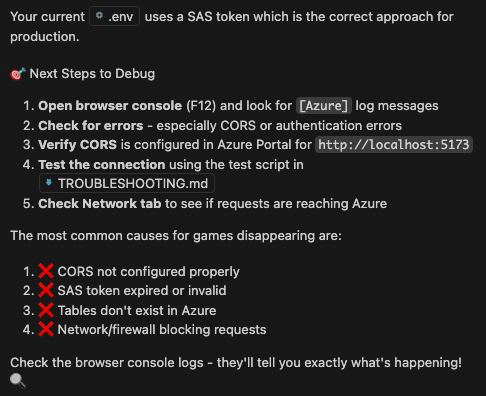
CORS looked like the culprit here. Once configured in the Storage Account, the application magically worked both locally and on Azure.
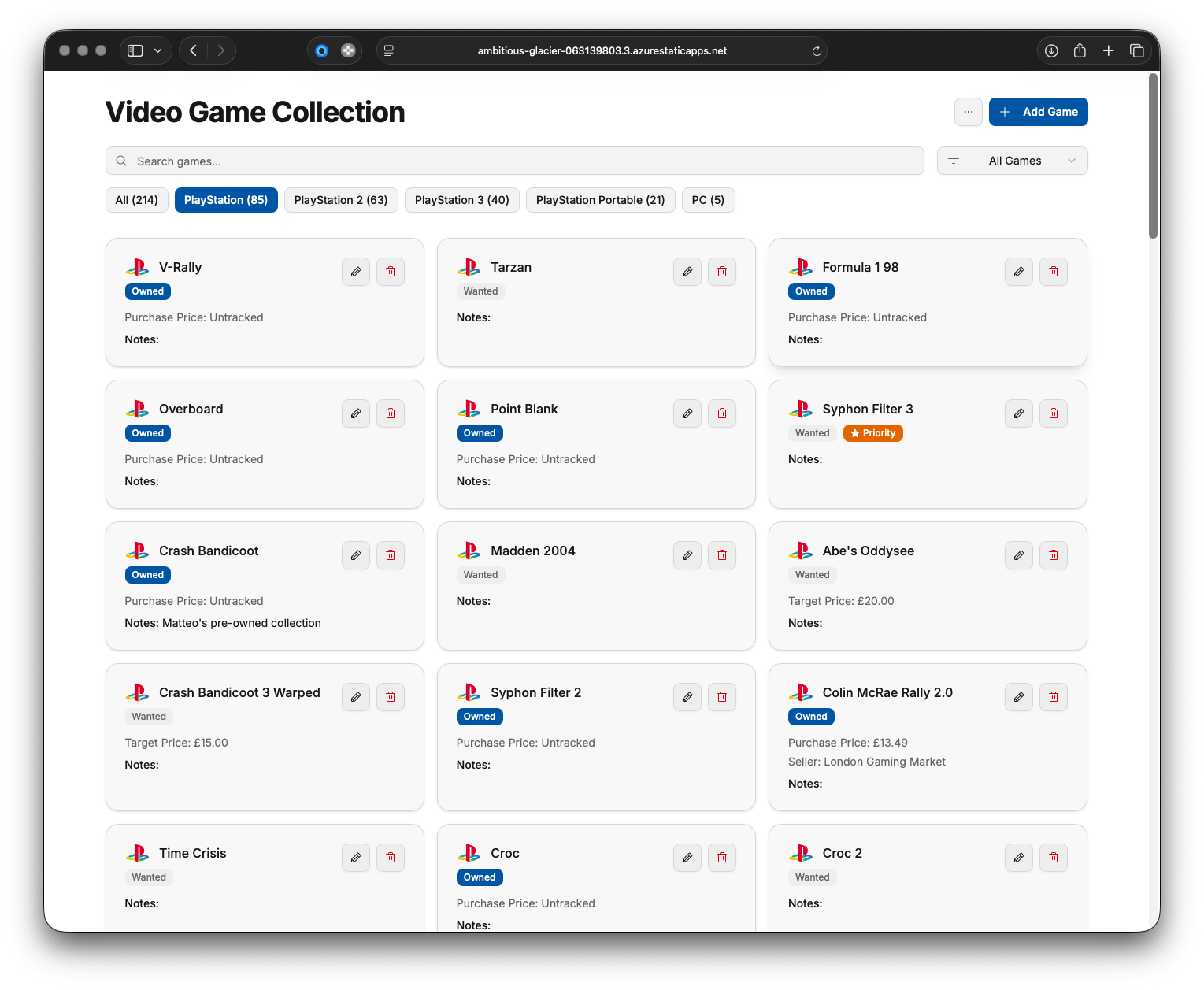
How long did it take?
As insane as it sounds, two hours. It was more the effort of getting the Spark right than anything else. I had two Pull Requests running 25 minutes from each other, and that was it:

Obviously, an experienced developer would be quicker!
What’s next?
If this was a real product and not just a one-off experiment, the logical next step would be to build more features using Coding Agents. That would be an extremely quick way of getting onboard with new development (or refactoring/bugfix) exploiting GenAI assistance to the max.
There might be more fixes or enhancements I can do on the fly with Agent Mode, or even coding them directly myself. The amount of documentation is brilliant and really helpful. Agent Mode even generates diagnostic tools and troubleshooting scripts when prompted correctly, which are super invaluable.
That is where real Frontier Firms are heading, harnessing a new way of working and leveraging change and disruption for industry-altering improvements. This is where we are heading, collectively.
If you are still worried about your programmes, it might be time to reconsider and trying to foster some experimentation, because if you are not doing it… your competitors surely are.