I am on the way to DDD North where I am going to talk about Agentic Engineering, and one of the key aspects of my talk is the generational evolution of GenAI tools for developers. Given the pace of change in our industry I believe we are already bsing a second generation of tools and assistants, and we are just about to leap on a third one - the reason being Agentic Memory.
With the current crop of tools, you are instructing agents via multiple layers of coding instructions, a constitution when it comes to SDD, etc. These are all artifacts you (or your team) need to maintain at all times to ensure the best results. Guardrails are implemented, practices described, etc. All because today your tools cannot learn directly from usage, expecting instructions or waivers before execution. Some workaround existed with tools like Basic Memory to persist memory files to be fed back to agents, but it was neither smooth nor fully integrated.
This changes with the implementation of Agentic Memory.
GitHub and Anthropic have them already, and there are signs of this being imminent for OpenAI too. This will lead to a new fundamental shift in maturity, leading to better interactions with models and agents.
Think about it this way: today you are telling what to do to an agent all the time. Correcting mistakes over and over again. You become more and more prescriptive, extending coding instructions to a potentially large and hard to maintain artifact.
With Agentic Memory, your corrections will stick. Agents will learn. And in enterprise environments this will lead to a much higher level of predictability, which is super valuable for heterogeneous teams.
It’s not early stages or something in a far distant future. If you have it enabled in your GitHub organisation, you will see a section in your repository settings (empty as I just enabled it for my repos):
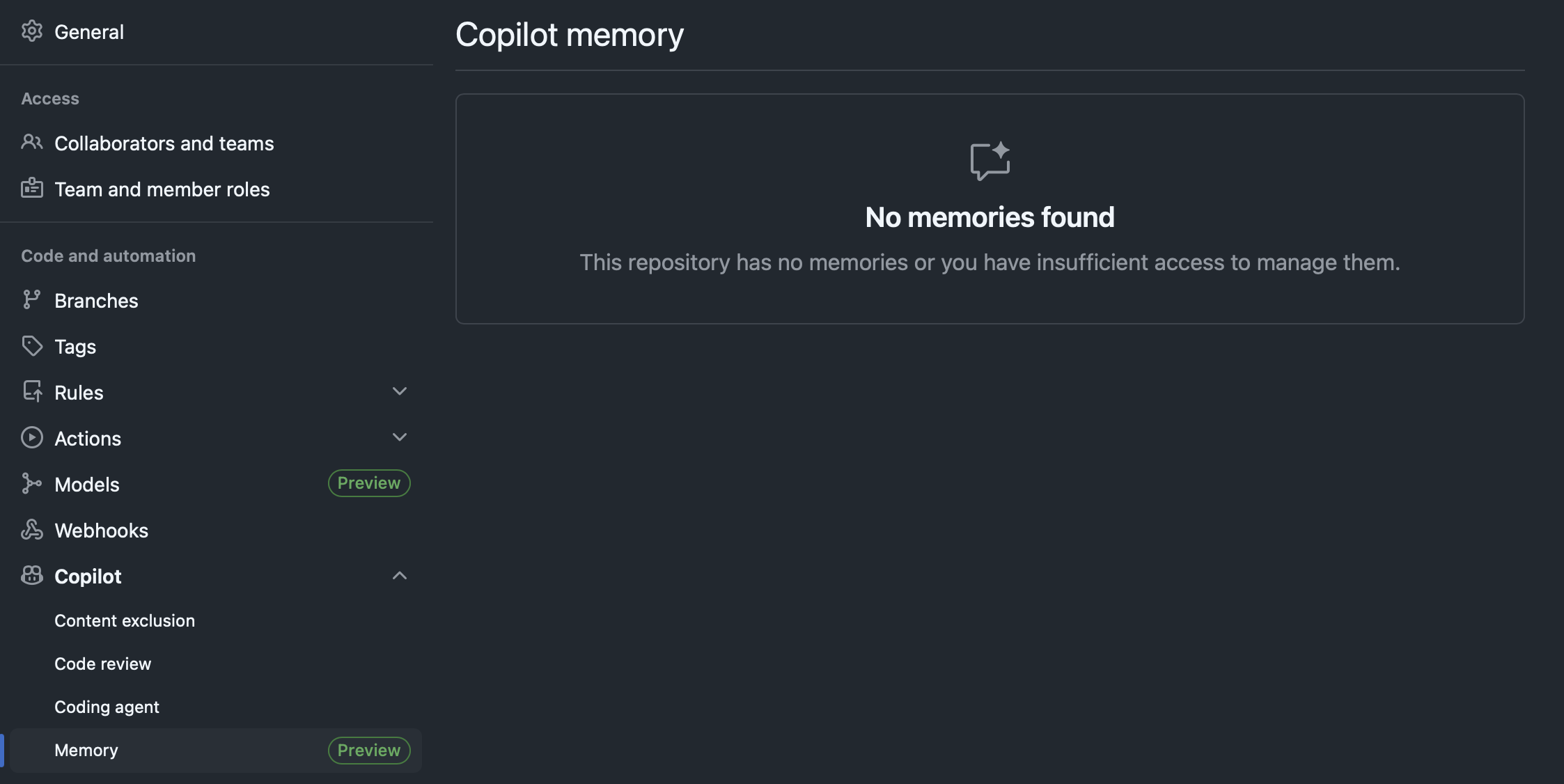
Documentation tells us they will be available as individual memories per session, so linked to either code reviews or Coding Agents sessions:

The most important remark here is that memories will be correlated to code that exists, so they will become part of the context in all intents and purposes, all self-contained in each repository. They will be flushed after a month if unused to prevent staleness, and retained otherwise.
This will be the next generational jump in DevEx for GenAI, so instructions will remain as guardrails whilst every repository will evolve by its direct usage. What becomes fundamental here is codifying enterprise- and organisation-wide instructions that leverage memories explicitly, rather than relying on a proliferation of repo-scoped memories, and it’s something we are already doing today with multi-layered instructions - so the core concept remains the same, with an enhanced execution.