The next logical step in Agentic Engineering happens when teams move from individual developer augmentation to agentic delegation. That’s where two key patterns start emerging: full delegation and local parallelisation.
Full delegation
This is the easiest one, and it usually involves agents both local and remote: you choose a requirement and hand it off to an agent entirely, remaining involved only for review and comments. Have a look at this example:
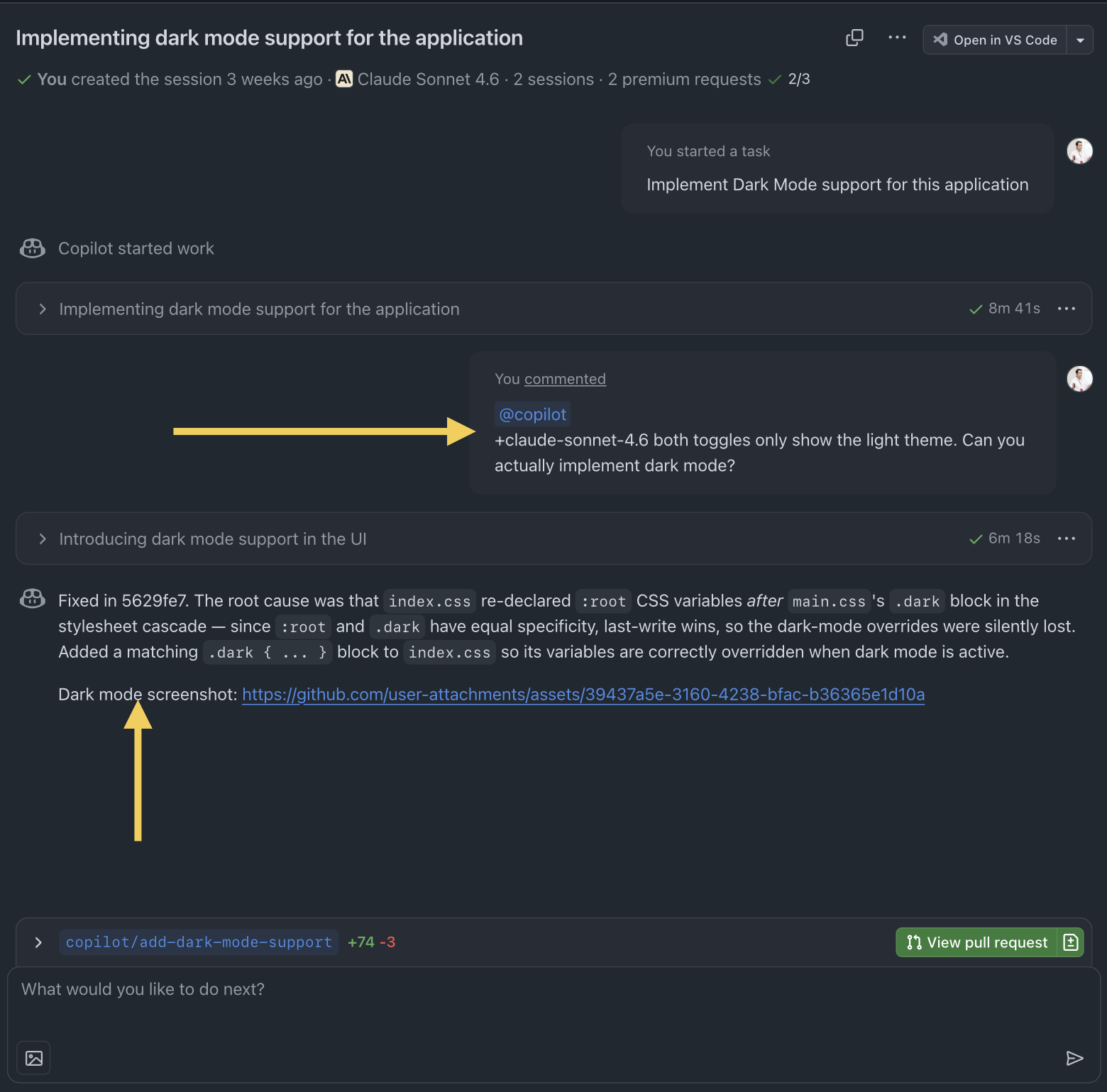
This is a typical example of full delegation: the discrete requirement is handed-off to the agent, which works on its own. Once the session is over, a developer can review the output and comment or even change model (like I did, moving from Codex to Sonnet). The agent continues to iterate.
The other interesting thing is that in this case my agent is going to provide me with evidence of the result. This is a super useful behavior which started recently: all I have to do is to check the output and validate.
This is obviously not applicable to everything, but in many cases it’s a very easy way of checking and allowing for quick iterations.
Local parallelisation
Local parallelisation gives me the ability of running multiple agents against the same requirement, eventually merging these changes. The big thing here is that agents will run in parallel in their own worktrees so they are independent of each other without a sprawling number of branches.
Phase 6 here comes from a SDD session I launched to implement some API changes, whilst the UI was being worked on in parallel by another agent. These changes are implemented via the Copilot CLI:
Using the CLI means that these sessions will run in unattended fashion, surfacing information in the chat window as always but without a continuous interaction (except for authorising tasks and commands, which remains up to you).
Fleet of agents
The Copilot CLI natively support fleets of agents, via a /fleet command. This will orchestrate the set of agents from a single session and drive execution with the specified models, commands, etc. It allows for complete parallelisation of work done via agents.
What’s next?
The next logical step would be running agent-friendly backlogs with a built-in persistence system acting as memory. I already said it’s going to be the next big thing didn’t I? 😀
An early example of this is Beads, which replaces the manual plan stage of each requirement with a fully-automated dependency graph, enabling multiple agents to work on a single, larger piece of work.