You keep running out of GitHub Copilot credits (or running into rate limits with other providers), and you wonder how to mitigate that?
It is a fairly frequent situation that tends to happen because users tend to one-shot an Agent request or just going back and forth with Copilot in Edit mode. Now… nothing wrong with that, however it’s inefficient.
Starting from here, we can start building an understanding of what actually happens when you interact with the service.
What can you do?
The context you use matters. The workspace you are working in matters. The prompts you use are super important. Given it’s not just a free-for-all anymore, you need to start optimising.
Once you have solid prompting foundations, introducing optimisation starts with model choice: you are using a horizontal orchestrator with access to many models, don’t just settle on one. Reasoning models are expensive and you should use them only when needed.
Then don’t forget to adjust the thinking effort where possible:
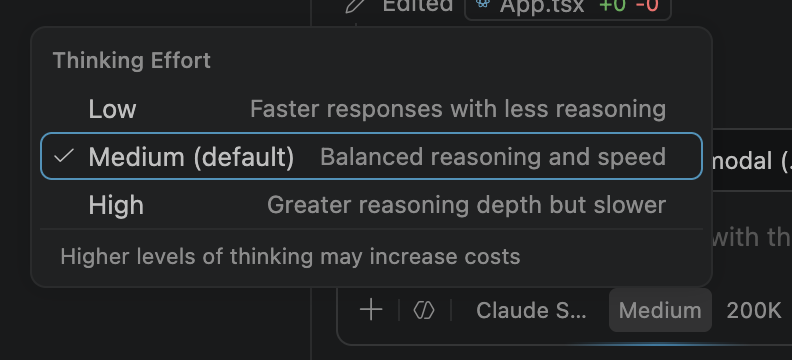
Even if you are using a mid-range model like Sonnet, you can control how much reasoning is used, and more often than not you don’t need High (or even Medium!) reasoning if you are implementing well-crafted specifications. Also don’t forget about smaller models (Haiku, Gemini Flash, etc.) as they are quite capable in deterministic implementations.
For the next level of optimisation, in my opinion, you need to get an in-depth understanding of what you are using.
You can start by looking at the internals. Using the Agent Debug Log panel you can drill-down to each step, and see what actually happens. And it becomes interesting…
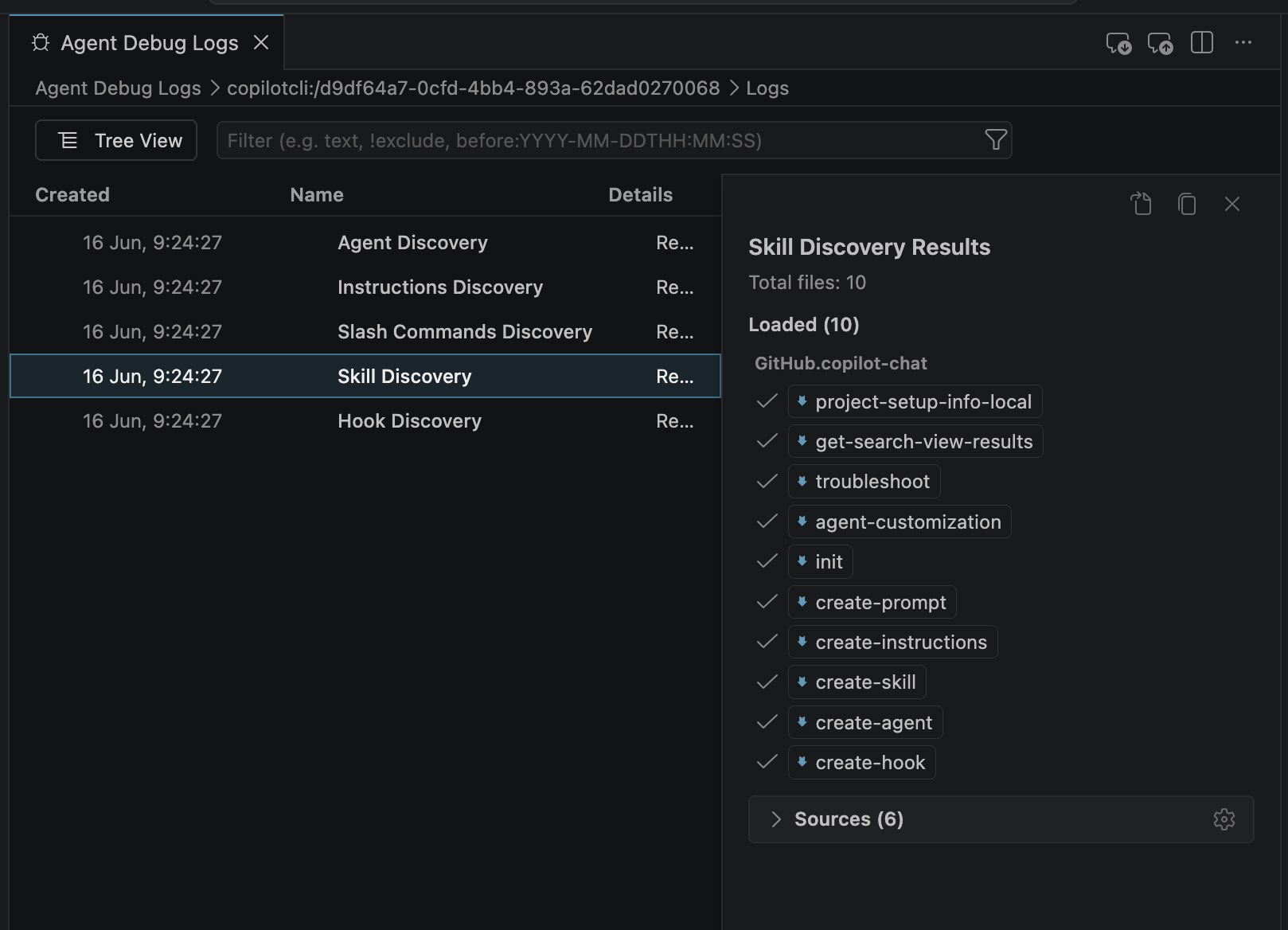
You will find that every time you use an interactive mode (Edit, Agents, etc.) the overhead can be significant. Default skills and slash commands, default tools, MCPs, etc. This means that every request you send that way will have a premium you can’t really see.
If you are working in interactive mode assume a 15-20% overhead by default between system tools, instructions, etc. (obviously much lower like below in Ask Mode).
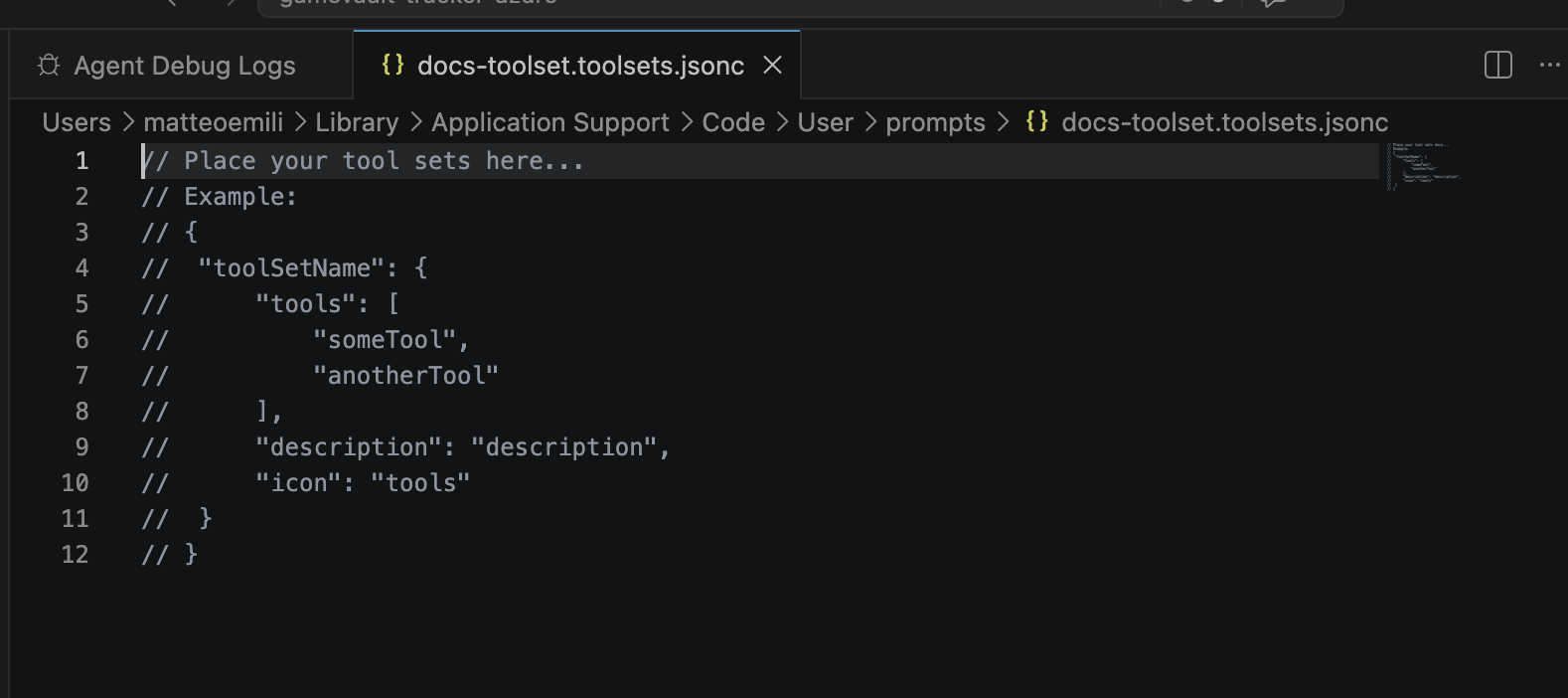
So it’s clear that managing your tools is another key task. Out of the box, Copilot uses a bunch of default tools that are injected in your context once the request is sent. Obviously you can tailor the tools with skills and reusable assets, however if you want to just reduce them you need to build a custom toolset mixing and matching what you actually need. It’s a JSON file.
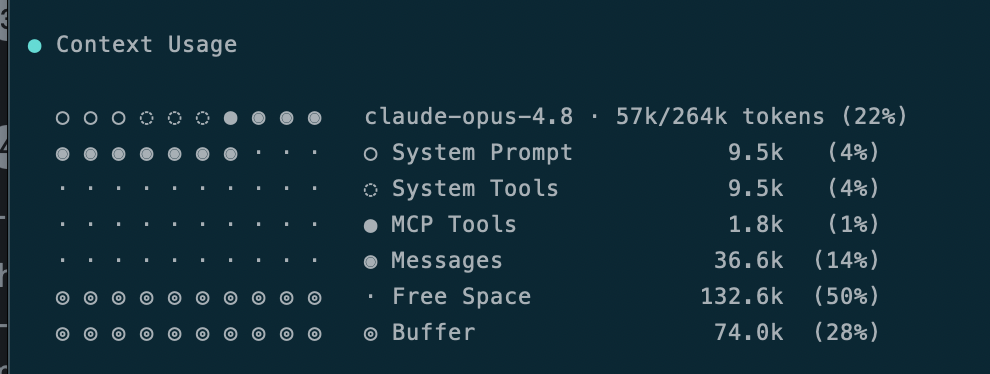
Compacting conversations is also an important tool you can use, not so much as to reduce the immediate token cost but rather to increase the quality of the output and reduce waste.
Think about it: we know models start hallucinating at around 75% of context window, so compaction solves the problem by generating an effective summary and handoff. It becomes really evident that if your model keeps hallucinating or looping you are literally wasting tokens.
Very handy to know however that compacting starts automatically at 80% usage however I suggest trying to manage this autonomously to facilitate handover, otherwise you will have significant flow interruptions.
What’s next?
This is pretty much all you can do by yourself. The next logical steps in this tokenomics reality we live in are all about scaling to team and organisation, and in particular:
- agent-friendly backlog systems
- reusable, composable team libraries
For the former, we already have Spec-driven development showing how to build an agent-friendly backlog system, all there is to do there is adopt it 😀 Tools like Beads and GasTown are the extra orchestration on top of the concept, however you can do most of it with a traditional Azure DevOps or Jira setup.
For the latter, we are getting there as an industry via reusable, outcome-driven orchestrators teams will grow as internal products. This is, weirdly enough, what I just finished talking about at DevOpsCon during one of the breaks, where the idea is that the platform does not change however the content of the platform will.
Eventually one of the things I also recommend teams do is to try and track token usage in their requirements so to build correlation between complexity, usage and solutions over time. It might seem like a repetitive exercise right now however you are going to build insights around how the team operates and how the organisation can benefit from different approaches.